Kaggle練習-Titanic Practice起手版 (TBC)
kaggle是一直聽到很有指標性練習的題目,網路上現在的相關文獻與分享也是非常多元,這邊已看到一些不錯文章,我再歸納成自己想法做心得分享。
kaggle題目 https://www.kaggle.com/c/titanic
首先來到背景介紹,這一題是kaggle的初級題目,算是machine learning(ML)的分類(classification)問題 — 生存/死亡,預測乘客搭了鐵達尼最後有無活了下來。
背景說明

看過電影都知道,鐵達尼號是死傷很慘烈的災難...,雖然用愛情作為包裝,活生生就是個幾乎全船死亡的意外事故,而kaggle這個活動,就是要來看看,這之中到底誰生存,誰死亡了。由下圖,我們可以看出,能否搭上救生艇是個關鍵因素。

我綜合了幾篇大大的文章(如最後reference),看得出來,最關鍵的因素如下:

我們可以知道,要做數據模型,變數好壞更甚於模型的選擇,因為誰可以搭上船,跟這個人本身的特質很有關係,是否有錢拉~是否是女生~是否是小孩???。
所以,這個比賽的關鍵重點,是能否先做出能讓模型套用的最佳變數組合,這之中又包括了一些資料處理、feature engineering還有模型配適等數據分析技術。

來從這幾個key point來深入剖析,分別從問題分析、資料匯入、資料清理、EDA(敘述統計)、變數選擇和模型選擇來簡單說明。關於做資料的步驟,我自己更喜歡的是Google Data Analytic Certificate的流程,課程順序就是做資料分析的順序,因為提到要一直ask question,這是工作以來我覺得真的很重要的事情!
1. 問題分析

從kaggle的overview頁籤,列出了問題說明還有評分方式,這題真的是kaggle的入門題目,因為題目好懂,評分方式也算很清楚(就是預測人數正確率越高就贏了XD),accuracy計算方式,就是二元分類矩陣的方法:
Accuracy = (TP + TN)/(TP + TN + FP + FN)
試想,你做預測時候,一定是猜測對方是0(死亡)或1(生存),然後你猜測的本身一定有個正確答案(0或1),所以你猜測的後的結果會有四種狀況,
- TP: 真的活著,你也猜他活著
- TN:真的死亡,你也猜他死亡
- FP:其實沒死,但你猜他死亡
- FN:真的死亡,但你猜他活著
所以正確率就是所有狀況之中的1+2的占比: 也就是 1+2/(1+2+3+4)
以上,是本題目的目標。
接下來,我參考了很多偏kaggler的文章,彙整完整步驟和讀書心得。
使用工具
我將使用的工具是Google的colab,以python程式碼進行。(免費又很popular的code)。這邊有個插曲,由於公司目前要使用Dataiku (DSS)雲端線上平台做資料分析,所以本題我也將用它來練習,所以會分DSS和和colab版本,先以DSS版本為主,我再把它全部化為python語法做更多練習。DSS版本因為要有授權,可以看看畫面清楚就好了,google colab步驟再說明詳盡一些。
2. 資料匯入
釐清題意後,要來開始玩資料了,首先就是insert data :D 輸入資料這一題目kaggle網站提供csv檔案,直接匯入我要拿來分析的工具。
鐵達尼提供的csv檔案本身就分為train和test,所以做資料處理時,一定都要處理到,屆時做模型結果比較時候才不會有誤差。

<Dataiku版本>
匯入csv檔案




test重複步驟,完成後會有下面二張dataset在flow內

<Colab版本>
寫python等於寫程式語言,按照分析的寫法,通常一開始要先把所有可能會用到的套件先install,本案例安裝pandas.seaborn.re.numpy.matplotlib等資料處理與繪圖會用到的套件

接著,一樣匯入train和test資料,python這邊直接先把它們append在一起成叫做df_data的dataset,並顯示前面五筆確認匯入的資料無誤。
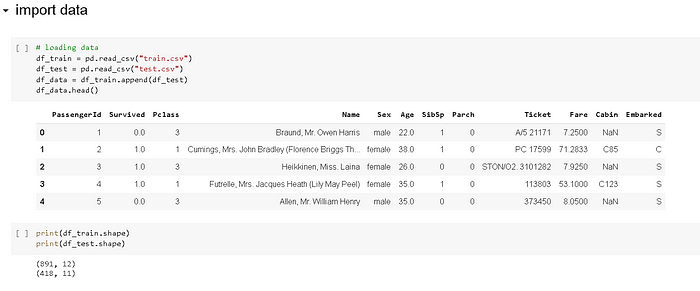
3. 資料清理
匯入資料時,DSS可看出資料有些不符合格式或有缺失值的狀況,才會部分顯示為紅色,因此,做分析前一定要有這部分的資料清理,有些是需要把文字格式的資料轉換為數值的處理。
<Dataiku版本>




接下來要再看看有沒有欄位還有missing的,因為這都會影響後續模型的計算,所以一定要仔細看清楚,發現age有missing


接著做Dummy Variable,也稱作one-hot encoding,這在類別變數是必須要做的處理,因為電腦只能讀懂0與1,所以要把像男生女生這樣的變數資料,轉換為0與1電腦好辨識的格式與內容,才能作分析。
以本分析來說,需要轉換的有Sex和Embarked,使用的函數為unfold

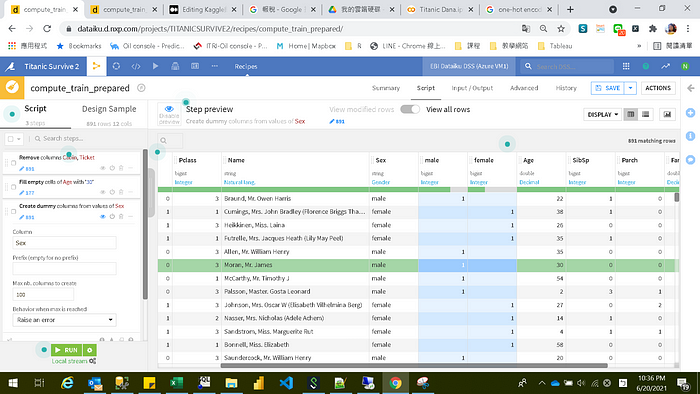
接下來,針對male和female二欄位,可以只保留一個,亦可代表本來的Sex欄位(只是male和female轉為1與0了),所以其中一個欄位可以刪除,保留的欄位空白補0,Sex欄位也可以刪除。

embarked也同理,但它原先有S、C和Q三個值,所以會有三個欄位,這時保留其中二個欄位就可以表示它屬於哪一個embarked了,因為假如有A、B、C三個班,如果你不是A也不是B,那一定就是C班了,所以n-1個欄位(本變數n=3)就可以表示資料的內容。

保留Q和S欄位,並將其補0,原先embarked欄位也記得要刪除。

這邊Name欄位,因為後須精進模型時其實會用到,所以先不刪除。
最後把recipe複製到test資料,也做一樣的資料清理與變換。

<Colab版本>
完全一樣步驟,只是因為是寫程式,所以有些程序要多寫一些檢查的步驟進來會比較完整。
這邊就先不做欄未刪除了,直接先檢查欄位格式

一樣先把embarked做轉換,python直接用get_dummies這個函數,並再刪除多餘的資訊,Age這邊是只將male轉為1,female轉為0,正式來說不算真的做dummy variable。


再來是fill有missing的欄位,同DSS,這邊是用mean(29.xxx)來補Age為空白的情況。

最後這一道,是因為上述dummy variable,只有embarked真的有用get_dummies這函數,所以另作的欄位,要再拚回原來的dataset,才有下方這一串處理。

4. EDA(敘述統計)
資料清理後,接下來要來看變數之間的關係與能表達的訊息,就是要開始瘋狂做EDA了。
做分析要先釐清題意,確定自己需要什麼資料,但是kaggle的好處是基本上它該要用的資料都直接給你了,不需要做些業務上的分析,不過我能做的就是多看資料間的關係並解讀可能的現象,幫助匯入模型時能使用更優良的變數進行運算。
不管是使用哪個工具,先畫出圖形就對了,當然也不能隨意拉出X與Y畫圖,也要從題意來思考,從上述背景說明來看,最可能相關變數為(1)年紀、(2)性別、(3)票務艙、(4)登船港口、(5)座位位置與(6)家庭狀況 有關,所以我先來看看這部分的結果:
(1)年紀
<Dataiku版本>
<Colab版本>
5. 變數選擇
6. 模型選擇
從大大的文章可以知道random forecast是在本題相對適合的模型,但因為最近剛好也在學習深度學習,我也用ANN來與它做比較。
Reference:
•https://aifreeblog.herokuapp.com/posts/64/Data_Analytics_in_Practice_Titanic/
- https://www.kaggle.com/shama123/logistic-regression-titanic
- https://yulongtsai.medium.com/https-medium-com-yulongtsai-titanic-top3-8e64741cc11f
top 3%大神的code: